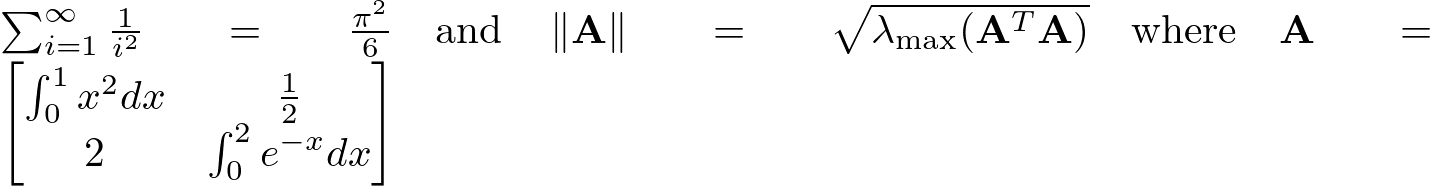本文记录参加书生大模型社区比赛的一些过程。
本次比赛 是上海 AI Lab 举办的书生大模型实战营(第六期)的社区活动,在算力平台 d.run 上使用沐曦算力,通过微调 VLM 等方法识别输入的公式图片,输出对应的 LaTex 文本。限定使用 InternVL3.5-1B 模型。
之前也有过类似比赛,实战营(第五期)举办了论文分类打榜赛。微调 LLM 对论文摘要进行学科分类。
任务
具体来说,输入图片均为 texlive 渲染得到的 LaTex 公式图片,输出应为对应的 LaTex 公式文本。
1 \sum _ {i=1}^ {\infty } \frac {1}{i^ 2} = \frac {\pi ^ 2}{6} \quad \text {and} \quad \left \| \mathbf {A} \right \| = \sqrt {\lambda _ {\max }(\mathbf {A}^ T\mathbf {A})} \quad \text {where} \quad \mathbf {A} = \begin {bmatrix} \int _ {0}^ {1} x^ 2 dx & \frac {1}{2} \\ 2 & \int _ {0}^ {2} e^ {-x} dx \end {bmatrix}
评估方式
哈希比较成功率: 模型生成的图片与参考图片哈希值完全相同 的样本比例。图像相似度 (直方图相似度/SSIM/MSE/特征点相似度 加权)高于阈值的样本比例。加权平均值 ,全面反映模型的性能。
提示:测试数据的图像可能经过增强
点击展开详情 本次比赛可能会涉及一些基础图像增强变换,包括但不限于:
几何与空间变换 旋转 (Rotation) 透视变换 (Perspective) 仿射变换 (Affine: 含缩放与错切) 镜头畸变 (Lens Distortion) 画布扩展与边缘裁剪 (Canvas Expansion & Border Trimming) 颜色与光照调整 颜色抖动 (Color Jitter: 含亮度与对比度) RGB 通道偏移 (RGB Shift) 色温调整 (Color Temperature) Gamma 校正 (Gamma Correction) 通道随机丢失 (Channel Dropout) 噪声干扰 高斯噪声 (Gaussian Noise) 椒盐噪声 (Salt & Pepper Noise) 泊松噪声 (Poisson Noise) 散斑噪声 (Speckle Noise) 模糊与画质损伤 高斯模糊 (Gaussian Blur) 运动模糊 (Motion Blur) JPEG 压缩伪影 (JPEG Artifacts) 评估数据包括两版,A榜 和 B榜,类似于验证集和测试集,样本均未公开。
资源
代码:提供了两份 Lora SFT 的 baseline,基于 ms-swift 的 demo 和基于 XTuner 的 demo ,均包括评估框架和微调代码。
数据:提供有一个包含 3000 个图像文本对的训练数据集,上面两个 demo 都使用该数据集。
奖金 :1st, 2nd, 3rd, 4-20th, 21-60th 分别有 6/4/3/2/1k RMB. 是真的我作证,因为上一期拿到了 1k.
InternVL3.5-1B 是 LLaVA 式的 VLM, 这类的 VLM 约等于 Vison Backbone + MLP + LLM,其中 MLP 相当于视觉和语言的桥梁,把视觉 token 映射到视觉语义共享的特征空间,作为 LLM 的视觉输入。
数据:①增加训练数据(寻找/合成);②图像数据增强 训练:③尝试不同的微调方式,如全量微调;调整微调不同部分的权重 寻求更大的增益:④因为有明确的奖励信号,适合用 RL 优化模型偏好,把输出对齐到合法的 LaTex 文本;⑤通过后处理约束输出 LaTex 文本的合法性 样本数量扩充
第一版数据生成器比较粗糙,数据扩充到 9k 分数有提升。扩充到 20k 反而 A 榜分数有下降。这时由于评测时间过长,B 榜分数出现了严重的滞后,根据 A 榜表现放弃了 20k 版本的数据。
数据清洗
数据增强
多打几个补丁
小乌龙
1 2 请根据图片中的公式生成对应的 latex 语法正确的公式文本。 *原 prompt:请根据图片中的公式生成对应的 latex 公式文本。
这是 native speaker 写出的中文句子?LLM 看了可能都不习惯,以后还是要多写作、多表达
一直瞎训提交 A 榜抽奖也没啥意思(主要是没啥进步空间了),不如趁这机会试试其他玩意
RL
小小的吐槽一下,怀疑比赛举办方没有 review 过 vibe coding 的评测框架代码,每种相似度评分都重复地进行预处理,以及实现了批量推理却没有使用,不知道是不是 B 榜出分缓慢的原因之一。
跑起来 GRPO 了,此时距比赛结束还有不到 48 小时,一看预计运行时间 40+ 小时,实际上更慢。中间还断了两次,感觉沐曦卡还不是特别稳定,国产算力任重道远。vllm 在沐曦上没找到合适环境,torch 版本太低,swift sample 也没调通,就龟速地一边推一遍训了。
log 里 clip_ratio=0、entropy 指标也在下降,Claude 说模型没学到啥,毕竟我看示例都是训了几百 ep,我这 1 ep 都跑不完,训了 600 steps,Lora 权重也没啥变化,有图为证,
约束解码/后处理 相似度评估真的有效吗
按照约束解码的思路,根据完整的 LaTex 文法约束 token 采样,但 LaTex 语法略显复杂,先从错误样本做个简单版本:
在生成的公式中观察到的错误有:
Claude 创建了一个类 LatexState 记录生成过程的各种状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @dataclass class LatexState : """追踪当前已生成序列的语法状态""" bracket_stack: list = field(default_factory=list ) env_stack: list = field(default_factory=list ) in_matrix_env: bool = False last_token_text: str = "" generated_text: str = "" MATRIX_ENVS = { "matrix" , "pmatrix" , "bmatrix" , "vmatrix" , "Vmatrix" , "smallmatrix" , "array" , "aligned" , "align" , "cases" , "gather" , "eqnarray" , }
基于 LatexState 的状态,定义了对应多种错误的检查函数,例如:
1 2 3 4 5 6 7 8 def check_ampersand_outside_matrix (candidate: str , state: LatexState ) -> bool : """ 错误类型1:没有矩阵环境时生成 & 返回 True 表示该 token 非法 """ if '&' in candidate and not state.in_matrix_env: return True return False
点击展开其他检查函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 def check_mismatched_brackets (candidate: str , state: LatexState ) -> bool : """ 错误类型2:生成不匹配的括号,如 (] 模拟将 candidate 加入当前括号栈,检查是否产生不匹配 """ PAIRS = {')' : '(' , ']' : '[' , '}' : '{' } OPEN = set ('([{' ) CLOSE = set (')]}' ) simulated_stack = list (state.bracket_stack) for ch in candidate: if ch in OPEN: simulated_stack.append(ch) elif ch in CLOSE: if not simulated_stack: return True if simulated_stack[-1 ] != PAIRS[ch]: return True simulated_stack.pop() return False def check_invalid_command (candidate: str , state: LatexState ) -> bool : """ 错误类型3:编造的命令,如 \vbeta, \invalidcmd 检测 candidate 中是否包含不在白名单的 LaTeX 命令 """ commands = re.findall(r'\\([a-zA-Z]+)' , candidate) for cmd in commands: if cmd not in VALID_COMMANDS: return True return False def check_consecutive_subscripts (candidate: str , state: LatexState ) -> bool : """ 错误类型4:数字或字母后出现连续下划线,如 b_6_4 检测合并后文本中是否有 x_y_z 的非法连续下标(未用{}包裹) """ combined = state.generated_text + candidate if re.search(r'(?<!\{)[^_{}]+_[^_{}]+_' , combined): return True return False def check_env_order_mismatch (candidate: str , state: LatexState ) -> bool : """ 错误类型5:\end{env} 与栈顶 \begin{env} 不匹配 如 \begin{array}\begin{pmatrix} 后出现 \end{array} """ ends = re.findall(r'\\end\{(\w+)\}' , candidate) simulated_stack = list (state.env_stack) for env in ends: if not simulated_stack: return True if simulated_stack[-1 ] != env: return True simulated_stack.pop() return False def check_illegal_characters (candidate: str , state: LatexState ) -> bool : """ 错误类型6:非法 Unicode 字符(中文、全角等) """ ILLEGAL_RANGES = [ (0x4E00 , 0x9FFF ), (0x3400 , 0x4DBF ), (0xFF00 , 0xFFEF ), (0x3000 , 0x303F ), (0x0080 , 0x009F ), ] for char in candidate: cp = ord (char) for start, end in ILLEGAL_RANGES: if start <= cp <= end: return True return False def check_double_superscript (candidate: str , state: LatexState ) -> bool : """ 错误类型7:连续上标,如 x^2^3(未用{}包裹) """ combined = state.generated_text + candidate if re.search(r'\^[^{}\^]+\^' , combined): return True return False def check_empty_group (candidate: str , state: LatexState ) -> bool : """ 错误类型8:空的花括号组 {}(通常无意义,在关键位置会导致渲染错误) """ combined = state.generated_text + candidate if re.search(r'\\(frac|sqrt|hat|bar|vec|dot)\{\}' , combined): return True return False
斯巴拉西,然后 Claude 给出了 logits processor 的实现
点击展开详情 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class LatexConstraintProcessor (LogitsProcessor ): def __init__ ( self, tokenizer, enabled_checkers: Optional [set ] = None , penalty: float = -float ('inf' verbose: bool = False , ): self .tokenizer = tokenizer self .penalty = penalty self .verbose = verbose self .state = LatexState() if enabled_checkers is None : self .checkers = CHECKERS else : self .checkers = {k: v for k, v in CHECKERS.items() if k in enabled_checkers} self ._vocab_decoded = self ._precompute_vocab(tokenizer) print (f"[LatexConstraintProcessor] 启用检查器: {list (self.checkers.keys())} " ) def _precompute_vocab (self, tokenizer ) -> dict : vocab = tokenizer.get_vocab() decoded = {} for token, idx in vocab.items(): try : decoded[idx] = tokenizer.convert_tokens_to_string([token]) except Exception: decoded[idx] = "" return decoded def __call__ ( self, input_ids: torch.LongTensor, scores: torch.FloatTensor, ) -> torch.FloatTensor: if input_ids.shape[1 ] > 0 : last_token_id = input_ids[0 , -1 ].item() last_text = self ._vocab_decoded.get(last_token_id, "" ) self .state.update(last_text) banned_ids = [] for token_id, candidate_text in self ._vocab_decoded.items(): for checker_name, checker_fn in self .checkers.items(): if checker_fn(candidate_text, self .state): banned_ids.append(token_id) if self .verbose: print (f"[banned] id={token_id} text={candidate_text!r} reason={checker_name} " ) break if banned_ids: scores[0 , banned_ids] = self .penalty return scores def reset (self ): """每次新的生成前重置状态""" self .state = LatexState()
遍历整个词表可还行,试一下果然慢得要死。而且模型开始无休止地吐 token ,猜测是 EOS token 也被 mask 了,
再检查发现 EOS token 后出现的都是 pad token,应该是批量推理的其他样本尚未结束生成。进而发现上面版本的 batchsize 错误,input_ids[0, -1] 和 scores[0, banned_ids] 仅处理了批次中的第一个样本,继续提示 Claude,
整理上面的代码,给出 LatexState 和 LogitsProcessor 的完整版本。
几轮提示和修改后,得到了一个勉强可用版本,不足之处在于把包含环境的复杂序列也在 token 级别处理,实际上应该从 token 流的角度考虑,但这样引入了太多复杂性,到此为止。
点击展开详情 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 class LatexConstraintProcessor (LogitsProcessor ): def __init__ ( self, tokenizer=None , model=None , penalty: float = -float ('inf' verbose: bool = False , ): if tokenizer is None : assert model is not None , ( "请传入 tokenizer 或 model:\n" " LatexConstraintProcessor(tokenizer=tokenizer)\n" " LatexConstraintProcessor(model=model)" ) from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained( model.name_or_path, trust_remote_code=True ) self .tokenizer = tokenizer self .penalty = penalty self .verbose = verbose self ._eos_token_id = tokenizer.eos_token_id special_ids = set (tokenizer.all_special_ids) for attr in ('eos_token_id' , 'bos_token_id' , 'pad_token_id' , 'unk_token_id' ): val = getattr (tokenizer, attr, None ) if val is not None : special_ids.add(val) self ._special_token_ids = list (special_ids) self ._vocab_decoded, self ._static_banned = self ._precompute_vocab(tokenizer, special_ids) self ._precompute_token_indices() self .states: list [LatexState] = [] print ( f"[LatexConstraintProcessor] " f"特殊token: {len (special_ids)} 个 " f"静态过滤: {len (self._static_banned)} 个 " f"动态检查词表: {len (self._vocab_decoded)} 个" ) def _is_legal_latex_char (self, text: str ) -> bool : """判断文本是否只含合法 LaTeX 字符""" LEGAL_PATTERN = re.compile ( r'^[' r'a-zA-Z0-9' r'\s' r'\\{}()\[\]' r'\+\-\*/=<>!&|^~' r'_\^' r'.,;:\'"`' r'#%' r']+$' ) ILLEGAL_RANGES = [ (0x4E00 , 0x9FFF ), (0x3400 , 0x4DBF ), (0x20000 , 0x2A6DF ), (0xFF00 , 0xFFEF ), (0x3000 , 0x303F ), (0x0080 , 0x009F ), (0xD800 , 0xDFFF ), (0xE000 , 0xF8FF ), ] for char in text: cp = ord (char) for start, end in ILLEGAL_RANGES: if start <= cp <= end: return False return bool (LEGAL_PATTERN.match (text)) def _precompute_vocab ( self, tokenizer, special_ids: set , ) -> tuple [dict [int , str ], torch.Tensor]: """ 返回: vocab_decoded: 合法 token 的 id → 文本(用于动态检查) static_banned: 非法字符 token 的 id tensor(静态屏蔽) """ vocab = tokenizer.get_vocab() static_banned = [] vocab_decoded = {} for token, idx in vocab.items(): if idx in special_ids: vocab_decoded[idx] = "" continue try : text = tokenizer.convert_tokens_to_string([token]) except Exception: vocab_decoded[idx] = "" continue if not self ._is_legal_latex_char(text): static_banned.append(idx) else : vocab_decoded[idx] = text return vocab_decoded, torch.tensor(static_banned, dtype=torch.long) def _precompute_token_indices (self ): """ 按字符内容预分组,供动态屏蔽 O(1) 查找: _tokens_contain[ch] → 以字符 ch 开头的所有 token id 列表 _end_env_ids[env] → 包含 \\end{env} 的 token id 列表 _cmd_token_ids → 包含未知命令的 token id 列表(静态) """ KEY_CHARS = ('^' , '_' , '&' , ']' , ')' , '}' ) self ._tokens_startwith: dict [str , list [int ]] = {ch: [] for ch in KEY_CHARS} self ._end_env_ids: dict [str , list [int ]] = {} invalid_cmd_ids = [] for token_id, text in self ._vocab_decoded.items(): if not text: continue for ch in KEY_CHARS: if text.lstrip().startswith(ch): self ._tokens_startwith[ch].append(token_id) m = re.search(r'\\end\{(\w+)\}' , text) if m: env = m.group(1 ) self ._end_env_ids.setdefault(env, []).append(token_id) commands = re.findall(r'\\([a-zA-Z]+)' , text) if any (cmd not in VALID_COMMANDS for cmd in commands): invalid_cmd_ids.append(token_id) if invalid_cmd_ids: extra = torch.tensor(invalid_cmd_ids, dtype=torch.long) self ._static_banned = torch.cat([self ._static_banned, extra]).unique() def _get_context_banned (self, state: LatexState ) -> list [int ]: """根据当前状态返回需要动态屏蔽的 token id""" banned = [] if not state.script_has_arg: banned.extend(self ._tokens_startwith['^' ]) banned.extend(self ._tokens_startwith['_' ]) elif state.script_just_completed and state.last_script_char: banned.extend(self ._tokens_startwith[state.last_script_char]) if not state.in_matrix_env: banned.extend(self ._tokens_startwith['&' ]) if state.bracket_stack: top = state.bracket_stack[-1 ] for illegal_close in BRACKET_MISMATCH.get(top, ()): banned.extend(self ._tokens_startwith[illegal_close]) else : for illegal_close in CLOSE_BRACKETS: banned.extend(self ._tokens_startwith[illegal_close]) if state.env_stack: top_env = state.env_stack[-1 ] for env, ids in self ._end_env_ids.items(): if env != top_env: banned.extend(ids) return banned def __call__ ( self, input_ids: torch.LongTensor, scores: torch.FloatTensor, ) -> torch.FloatTensor: batch_size = input_ids.shape[0 ] device = scores.device if len (self .states) != batch_size: self .states = [LatexState() for _ in range (batch_size)] if self ._static_banned.device != device: self ._static_banned = self ._static_banned.to(device) for i in range (batch_size): if self ._eos_token_id is not None : if (input_ids[i] == self ._eos_token_id).any (): continue if input_ids.shape[1 ] > 0 : last_id = input_ids[i, -1 ].item() last_text = self ._vocab_decoded.get(last_id, "" ) self .states[i].update(last_text) if self .verbose: print ( f"[batch={i} ] last_token={last_text!r} " f"env_stack={self.states[i].env_stack} " f"bracket_stack={self.states[i].bracket_stack} " f"in_matrix={self.states[i].in_matrix_env} " ) scores[i, self ._static_banned] = self .penalty context_banned = self ._get_context_banned(self .states[i]) if context_banned: scores[i, context_banned] = self .penalty for sp_id in self ._special_token_ids: scores[:, sp_id] = scores[:, sp_id].clamp(min =0 ) return scores def reset (self ): """每次新的 generate 调用前重置所有状态""" self .states = []
效果
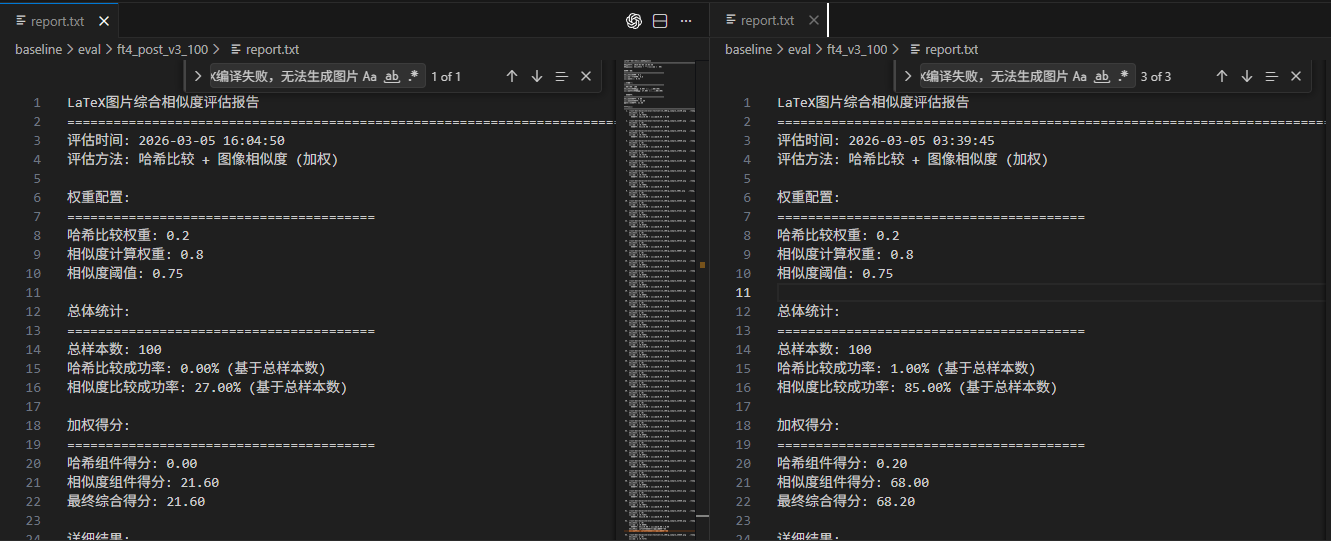
跑评测时发现某些情况会报错,图片成功渲染了相似度却通通是 0,细察发现图片读取部分有问题,
想了下,比赛过程有些缺乏章法,接近炼丹了。
应该尽早构造验证集和本地评测流程,检查错误样本。 科学炼丹:应该排实验计划,对每个有希望的方向进行试训。 应该尽早投入比赛。。好吧其实没邀请对象没有那么多算力。 拥抱 AI 力度不够(还是舍不得买 Claude,以及完全放手给 Coding Agent)智谱。(好吧有 Codex 已经满足了) 比第一次有进步 把 LLM 的知识蒸馏给自己 对于可靠系统 vibe coding requires review. 除了最初版的数据生成器丢失了,本次比赛产生的各种未经整理的代码放在了 kafmws/VLM-formula-recognition-dataset.git
增加视觉 token 数量、增大图像输入分辨率,也是显而易见的方向。但担心会破坏预训练模型的视觉特征提取能力,没尝试这些脑海里一闪而过的念头,还是有些可惜。RL 和约束解码也尝试太晚,没有成功应用到提交中。
2026/03/02